JPA Bulk Insert
 ordilov / 2022. 5. 14
ordilov / 2022. 5. 14대량의 데이터를 Insert할 때
적은 데이터를 insert 한다면 DB와 네트워크 연결이 시간이 제일 오래 소요되기 때문에 개수가 늘어도 큰 차이가 나지 않습니다. 하지만 대량의 데이터를 입력한다면 방법에 따라 성능이 많이 차이날 수 있습니다. 성능을 향상시키기 위한 기본적인 방법은 다음과 같습니다.
트랜잭션을 하나로 묶기
start transaction;
insert into table1 (id, name) values (1, 'name1');
insert into table1 (id, name) values (2, 'name2');
commit;
트랜잭션을 열고 닫는 데도 시간이 들기 때문에 작업을 트랜잭션 하나로 묶어주면 조금이라도 성능이 올라갑니다.
Bulk insert 사용하기
insert into table1 (id, name) values (1, 'name1'), (2, 'name2');
MySQL에서는 Bulk Insert라고 불리는 방법으로, 여러 row를 한 번에 입력하는 방법입니다. 이렇게 여러 row를 입력하는 경우 unique 제약조건이나, 외래 키 제약조건을 임시적으로 꺼두면 성능이 더 올라갈 수 있습니다.
SET unique_checks=0;
SET foreign_key_checks=0;
... insert
SET unique_checks=1;
SET foreign_key_checks=1;
여러 row를 한 번에 insert하는 경우에 데이터 패킷의 크기가 너무 커서 못 받을 수 있습니다.
show global variables like 'max_allowed_packet'
이 때 필요한만큼 max_allowed_packet 크기를 키워주면 됩니다.
JPA Bulk Insert
JPA에는 명시적으로 bulk insert를 하는 방법이 존재하지 않습니다. JPA에서 insert하는 메소드는 persist() 하나로, 컬렉션을 한 번에 저장하는 방법은 존재하지 않습니다. 하지만 Data JPA의 JpaRepository에서는 saveAll() 메소드가 존재합니다.
@Transactional
@Override
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null!");
List<S> result = new ArrayList<>();
for (S entity : entities) {
result.add(save(entity));
}
return result;
}
내부 구현을 살펴보면 saveAll() 메소드도 persist를 반복문으로 처리하는 것으로 다른 점이 없어 보입니다. 그럼에도 insert를 여러 개 할 경우 save() 대신 saveAll()을 써야하는 이유가 있습니다.
- 메소드를 여러번 호출하는 것과 한 번 호출하는 것만으로도 차이가 있습니다.
- @Transactional 어노테이션으로 새로운 트랜잭션 호출에 따른 시간 차이가 있습니다.
save() 메소드는 @Transactional 어노테이션이 존재합니다.
@Transactional 의 기본 전파 타입은 REQUIRED로 호출 시 새로운 트랜잭션이 생성됩니다.
따라서 호출 시마다 트랜잭션을 생성하게 되어 위에서 설명한 트랜잭션을 하나로 묶기조차 안되는 상태가 됩니다.
반면 saveAll()을 사용하는 경우 클래스 내부에서 save()를 호출하게 되는데 이 경우 Self-Invocation이 발생하여 트랜잭션이 생성되지 않습니다.
따라서 saveAll() 메소드의 @Transactional 어노테이션의 트랜잭션만 생성되어 트랜잭션이 하나로 묶이게 됩니다.
이 결과로 1만건만 테스트해봐도 42초와 5초 차이로 큰 성능 차이가 나는 것을 확인할 수 있습니다.

하지만 hibernate에서 생성되는 sql문은 여전히 여러 개의 insert문을 보내는 방식입니다.
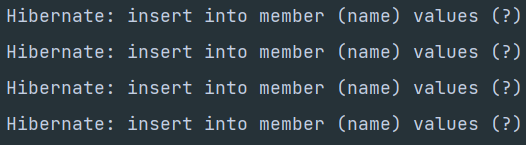
bulk insert로 sql문을 하나로 보내 성능을 향상시키려면 몇 가지 설정이 더 필요합니다.
Batch Size 설정
jdbc batch_size 값을 설정하면 크기만큼 sql문을 모아서 한 번에 DB 서버에 요청합니다.
batch_size가 정해져있는 이유는 모든 엔티티가 영속성 컨텍스트에 올라가면 OutOfMemoryException이 발생할 수 있어
batch_size를 기준으로 flush()와 clear() 작업을 진행해서 입니다.
spring.jpa.properties.hibernate.jdbc.batch_size: 20
order_inserts, order_updates 설정
같은 테이블에 대한 insert나 update가 모여 있지 않으면 batch 처리를 할 수 없습니다.
order_inserts 와 order_updates를 설졍해주면 같은 테이블에 insert끼리 묶어줍니다.
spring.jpa.properties.hibernate.order_inserts: true
spring.jpa.properties.hibernate.order_updates: true
mysql datasource url 설정
spring.datasource.url: jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true&profileSQL=true&logger=Slf4JLogger
rewriteBatchedStatements 옵션을 적용해주면 여러 insert 쿼리를 bulk insert 방식으로 재작성해줍니다.
이렇게 재작성된 쿼리는 Hibernate에 찍히는 SQL 로그와 달라지는데 바뀐 쿼리를 보고 싶은 경우
profileSQL=true 를 추가해주면 실제 mysql 쿼리를 볼 수 있습니다.
Hibernate: insert into member (name, id) values (?, ?)
Hibernate: insert into member (name, id) values (?, ?)
Hibernate: insert into member (name, id) values (?, ?)
Mon May 16 17:08:39 KST 2022 INFO: [QUERY] insert into member (name, id) values ('0', 1),('1', 2),('2', 3)
Identity 전략 문제
MySQL에서 Id 자동 생성 전략을 사용하는 경우 Identity 전략을 주로 사용합니다. 문제는 Identity 전략의 경우 다음 Id를 받아오기 위해서 insert를 해야하기 때문에 bulk insert 작업을 지원하지 않습니다. 따라서 bulk insert를 사용하려면 2가지 해결책이 있습니다.
해결책 1. Id 자동 생성 전략 변경
Id 자동 전략을 Sequence 전략이나 Table 전략으로 변경하면 bulk insert가 가능합니다. 하지만 단순히 Sequence 전략으로 바꾸기만 하면 성능은 더 안 좋아지게 됩니다. Sequence 전략을 사용하면 insert하기 전에 다음 id를 찾는 select문과 다음 id를 설정하는 update문이 나가게 됩니다.
Hibernate: select next_val as id_val from hibernate_sequence for update
Hibernate: update hibernate_sequence set next_val= ? where next_val=?
기본 id 생성은 하나씩 생성되기 때문에 insert하기 전에 매번 두 개의 쿼리가 더 나가게 됩니다. 따라서 생성해서 사용할 Id 범위를 지정해줘야합니다.
@Id
@GenericGenerator(
name = "sequence-generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@Parameter(name = "sequence_name", value = "hibernate_sequence"),
@Parameter(name = "optimizer", value = "pooled"),
@Parameter(name = "initial_value", value = "1"),
@Parameter(name = "increment_size", value = "100")
}
)
@GeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "SequenceGenerator"
)
private Long id;
increment_size를 지정해주어 크기만큼의 id는 조회나 업데이트 없이 생성할 수 있게 됩니다.
해결책 2: JDBC 사용하기
JPA를 꼭 써야만 하는 게 아니라면 bulk insert 작업을 JDBC로 분리할 수도 있습니다. jdbcTemplate의 batchUpdate() 메서드를 사용해 bulk insert가 가능해집니다.
jdbcTemplate.batchUpdate("INSERT INTO MEMBER(`NAME`) VALUES(?)",
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setString(1, "member" + i);
}
@Override
public int getBatchSize() {
return 1000;
}
});
결론
JPA로만 작성한다면 키 자동 생성 전략을 바꾸는 게 좋습니다. 하지만 JDBC를 사용한다면 키 자동 생성 전략을 그대로 사용할 수 있고 성능도 전반적으로 더 빨랐습니다. 다른 DB를 쓰거나 설정이 달라진다면 결과가 다를 수 있지만 MySQL 기준으로 데이터 크기가 커질수록 JDBC 쪽이 성능이 더 좋은 것을 확인할 수 있었습니다. 물론 두 방법 어느 쪽을 사용하더라도 사용하지 않는 쪽에 비해 큰 성능 차이를 확인할 수 있습니다.
